System Design Part 2 - How we approach
The article is still in draft stage.
Before we dig into various aspects of system designs, we shall first review and retrospect where we start when asked for designing a system.
High-Level Architecture¶
We can start with a high-level architecture, similar to Figure-1 below. Before long, you will find that nearly majority of systems you are about to design follow the same pattern. A client sends a request to a server, and then the server queries a database. The database sends back some data or confirmation and the server optionally processes the data before sending a response to the client.
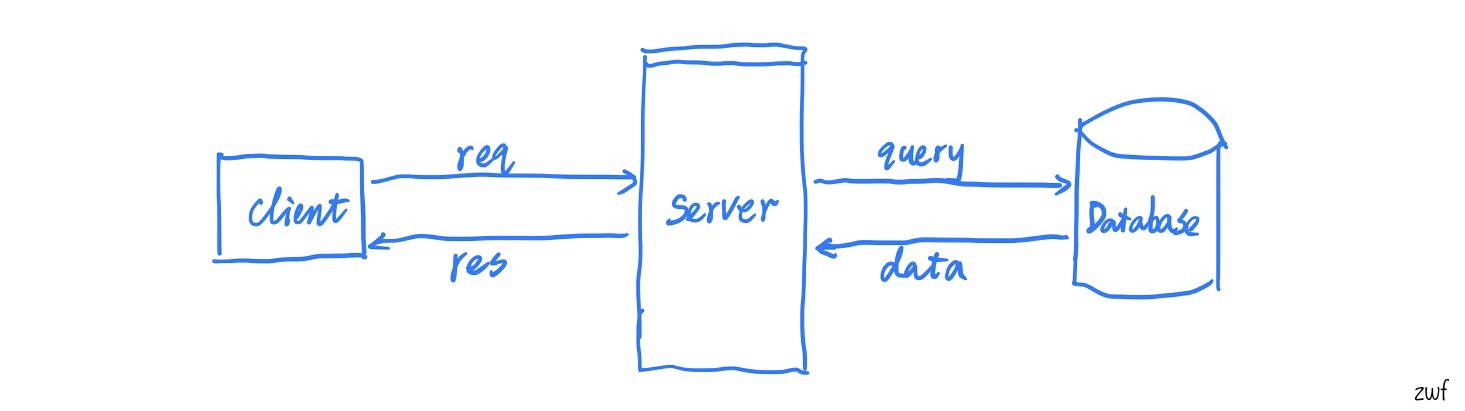
This diagram seems specific to an online system, for example a website, but can be applied to many problems if you think of the client, server, database in a more general way.
client can be: a real user, a web browser, a programming language library, a console or terminal, a batch job driver
server can be: any server that accepts requests from clients and responds accordingly. For example, a web server, a load balancer, a DNS server, a cache system, a batch job master server
database can be: any system that persists any data for future usage
Examples of Systems¶
Let’s review some examples.
URL Shortening System¶
In a URL shortening system (commonly asked in a technical interview), a client can be a website similar to bitly.com, which interacts with users who wants to shorten a long link in his hand. Once a user enters his link in the text box and click the Shorten button, a http request will be sent to a remote server with the link to be shortened and optionally the user’s information if she/he logins in.
In a small system, the server might just be a single machine that listens a TCP/IP port and exchanges data with outside world. The server processes the request, namely shortening the provided link by using some common techniques like hashing, and store relevant data in a database that can be relational database like MySQL, PostgresSQL or non-relational database such as MongoDB, Cassandra, etc.
In a large system that serves millions of users, the server is actually a distributed system that probably comprise of load balancer, tons of commodity machines running the same web service. Additionally, a caching layer will be placed in an appropriate position (we shall revisit more details later about caching system). There will be clusters of database instances which are either leader(s) or followers (a side note: I will avoid using master/slave term as much as possible, but they are the same concepts as leader/follower.).
Summary of URL Shortening System
Client: a real user or websites or Javascript that interacts with servers
Server: a web server listens on 80 or 433 port, or a cluster of servers and load balancers
Database: MySQL or PostgresSQL, or MongoDB, DynamoDB, Cassandra
In-memory Caching System¶
Caching layer is commonly found in many software systems. A famous example is memcached - an open source key-value based in-memory caching system.
In such a system, there might exist a variety of types of clients. Libraries for major programming languages will be available (such as here for Java, here for Python, and here for PHP). In fact, you can even use telnet to interact with memcached server.
On the server side, usually it uses a hash table in memory and the table size can grow to as much as the memory capacity. A special characteristic about caching system is that it usually doesn’t have a persistent layer. The primary reason is that caching system is not source of truth for the data.
Summary of In-memory Caching System
Client: Java/Python/PHP library or telnet
Server: a server with a big hash table or a cluster of servers
Database: usually no persistent layer
A Batch Processing System¶
Batch processing system is quite different from the above two in the first glance. Common batch processing includes Hadoop and Spark. While paradigm of designing is a bit different, we can still manage to use the abstract architecture to describe them.
In such a system, a driver program can be regarded as a client. It initiates a batch processing job and submits it to the cluster of the system. The system comprises of master nodes and worker nodes. Master nodes respond to clients’ requests and coordinate jobs with worker nodes, which execute tasks independently.
This cluster usually relies on distributed file system to persist data where we can refer as the “database” for the batch process system. HDFS is an open sourced distributed file system commonly used in the industry.
Summary of Batching Processing System
Client: a driver program
Server: the cluster of the system which has master nodes and worker nodes
Database: a distributed file system.
How to Differentiate¶
Surprisingly, the above three systems are quite different but can all be described with a single formula: client - server - database. If it applies to all systems, what is the point of system design? There must be some unique aspects about each particular system so that the design is essential in building and maintaining it.
Systematically, two types of requirements make a system unique regardless of how it is similar to any other system you encountered:
- Functional Requirements
- Non-Functional Requirements
Functional Requirements
These requirements describe the functionalities the system provide. In the URL shortening system, the requirements are: shorten a given URL and store it, retrieve original URL given a shortened URL; In the distributed caching system, the requirements are: store a piece of data associated with a key, retrieve the data with given key. When designing these systems, you have to make sure the system will correctly satisfy these requirements.
Correct implementation is the key, which requires you to: * Understand the problem you are solving deeply * Know the use cases of the system * Take care of corner cases * Leverage known algorithms and data structures or devise your own
Often, we easily overlook the importance of the functional requirements and focus too much on the non-functional requirements. Consequently, we need to rework the design later or deviate from the initial goal of creating the system.
Non-functional Requirements
These requirements describe how well the system will serve its functionalities. Usually, it is to ensure: user experience, data integrity, cost effectiveness, low maintenance effort, etc. With these goals in mind, you system needs to take into consideration of a subset of the following things:
- The availability of the system (it should be the same for a single user or a billion of users)
- The latency of responding client requests
- The consistency of the data (whether it is consistent for two different users and/or at two different times and/or in two different geolocations)
- The cost (machines, development, maintenance)
Different systems have different requirements, which make them differentiated from others. In URL shortening system, you need to keep it up running 7/24 and ensure generating the shortened URL quickly enough to make user believe it is worth their effort in using the tool rather than retrieving the long URL directly from their notebook. In the distributed caching system, the system should guarantee a high level of consistency of the data it caches. When a user updates the value of a key, another user should see the change of the same key after a short period of time.
There are many techniques for satisfying these non-functional requirements, and we shall discuss them in details separately.
Summary¶
When tasked with a system design, it's helpful if we can systematically approach it. The general suggestion here is to:
- Start with exploring the functional requirements of the system
- Build a high-level architecture of the system
- Scope the non-functional requirements and examine the trade-off of different factors